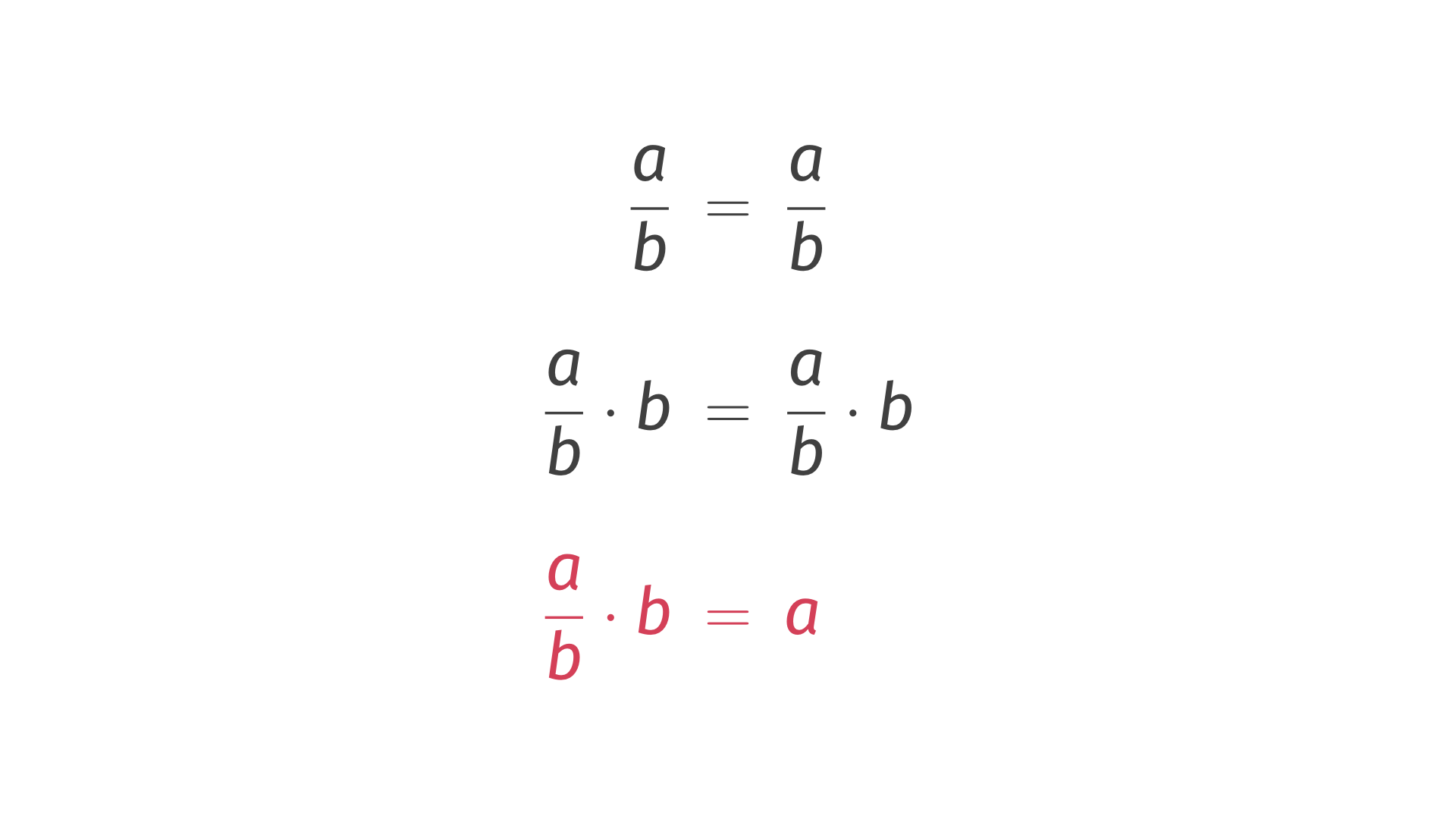Machine transcript
Lovely. Good afternoon, ladies and gentlemen, it's wonderful to be here with you today,
my first GeeCON, I'm excited to be here. I'm here to talk about testing, but before
I start, allow me to introduce myself really briefly. My name is Jan Stępień, I'm based
in Berlin, where I work at INNOQ, we're a consultancy, and as a consultant, I help people
build better software, sometimes as a software developer, sometimes as an architect, or a
trainer.
Enough about me, let's talk about you. My goal for today is to make you better
at testing. I'm sure that you write excellent tests, and I want you to keep writing those
tests. I want to give you another tool, another very interesting tool which can help you tackle
those most difficult cases, those really special systems under test which require particular
attention.
Let me start with a general question. Why do we test in the first place? Because
we don't need to, but we do anyway. One could say it's because of quality, quality of the
software we build, but I think that's nonsense. We can manually go through user stories, click
through the interface, and see that the database produces the right results and saves the right
data, and the quality is there. But we don't do it because we don't have time. So, in our
case, testing is all about automation. We want to automatically get the same assurances
but without any human input. And we automate so many things already, right?
We automate
our builds in our CI pipelines, we automate our provisioning with Terraform, Ansible,
you name it, and then finally, using continuous deployment, continuous delivery, we automatically
push all this stuff to production and it just works. It does so, among other things, thanks
to testing. Just like Fred George said yesterday, the day before, you won't deploy 600 times
a week if you don't have all those steps automated and taken care of, right? This is a prerequisite.
And tests belong to this group. So let's talk about the story of automation and maybe quality,
keeping Slido in mind. I would love to have your questions. Ask questions, upvote questions
of others. And, yes, let's talk about fitness tracking. This is our system under test. Back
when I was running, I used to have such a thing.
This is what I call business logic.
It's not a whole lot of it. It's a very simple case. I'm using raw numbers. But we ended
up with such a function, and now it's our task before we start, say, refactoring, for
example, we need some tests to make sure that the existing behaviour remains in place and
nothing falls apart.
So, we can write a handful of tests. For example, those three points
might be good enough. I'm ignoring the divide by zero case because it's not really meaningful,
so it's not a behaviour we want to test for and explicitly preserve in the refactoring.
So we look at those three cases and we're like, this might be enough, and if it's not,
how many more tests would we need to be certain that our system is sufficiently well tested?
Ten more, a hundred more, a thousand more? It's difficult to say. And also, what led
us to those particular values? Are they special in any way? Particularly interesting? Do
they literally appear in user stories?
Let's move things around a little bit. I extracted
all the values into a single collection, a single table, a list of inputs and expected
outputs, and then the assertion is completely decoupled from actual values. They are fed
from outside.
Now, with this thing, I want us to take a step back and talk to a domain
expert in this, in the world of fitness tracking to gain a better understanding of what we
are actually testing. Our domain expert will be our primary school math teacher.
A over
B equals A over B. If we multiply both sides by B and simplify the right side, we end up
with the following property. That's a key word for today. That's a property. We got
it thanks to a conversation with an expert who knows the domain better than we do as
software specialists.
Now we can take this property and put it in this piece of code
we wrote before. Notice what is changing. Something has changed inside of the assertion.
That's cool. But what is far more interesting is the fact that we don't need return values
of this function any more. We don't care what those return values are. We just keep feeding
inputs, and for arbitrary inputs, we should always - we should always see this property
being satisfied. So, what would prevent us from generating more and more completely arbitrary
inputs, hopefully exercising various exciting edge cases, and see whether the property
holds for all of them?
Exactly this reasoning, this approach is called generative or property-based
testing, where we subject our properties to large volumes of automatically generated
inputs. The approach is 20 years old. It was published in 1999. The first library implementing
it was called QuickCheck. It comes from the functional programming world, but it quickly
moved to other domains and got implemented in other programming languages.
In Java, we
have at least two libraries implementing this principle. Let's take a look how this
property, this assertion, would look like when expressed in those libraries. The first
one is JUnit QuickCheck. It looks like nearly like normal JUnit, but instead of having this
@test annotations, we have those @property annotations. It looks a bit different because
those functions have parameters. Thanks to this @property annotation, the test framework
generates values having read the types of arguments, generates arbitrary values of those types and
feeds them into our function, running it, I think, by default 100 times, but it's a
configurable parameter, so, if you want to be really sure, you can run it overnight on
your CI.
That's one thing. Another library which I like a lot because it's a bit less
annotation-heavy and more explicit and reads like English is QuickTheories. It looks like
this. In QuickTheories, we can say for all integers which are positive, and for any double,
check that the following holds. That's exactly what we wrote in plain English a couple of
slides before.
So, we see we have built-in generators of values, simple numbers. We have
also generators of strings, and we can say I want only ASCII strings, or I want alphanumeric
strings, or some very exciting strings. Now let's run this test against our function.
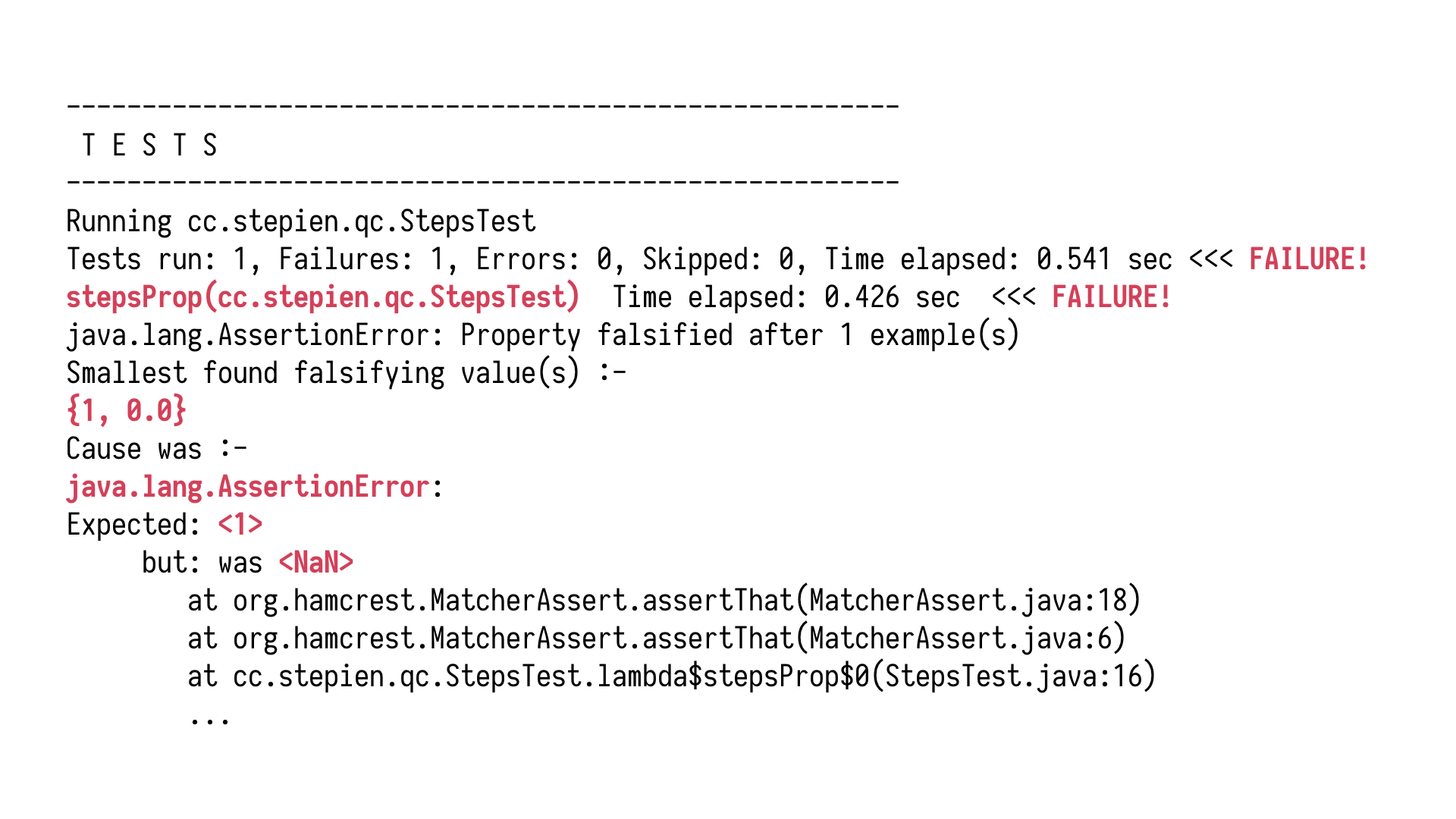
We end up with an error which is not all that surprising, right? If we zoom in, we
see that it's an assertion error. The assertion of the equality check has failed. We see
those two values which were fed into the function which led to the problem. One and zero. The
smallest found falsifying value. For those values, something doesn't work. We expected
one but not a number. We can't change mathematics. All we can do is either work with our system
under test, or our property, and try to somehow narrow it down so that it generates values
only within our domain. Values legal in our world.
Let's return to the property and take
a look at this generator of doubles. It's not any double. It's any double which is not
zero. After a chat with our domain expert, we decide that a ten is a good value to begin
with. Nobody wants an average for less than ten seconds of steps.
So, with ten in place,
we can say that we want all doubles between ten and one million, for example. Or, an alternative
approach, we can return to the previous version and add a call to assuming which takes a predicate.
Within two values which are generated, it says, yes, those values are okay, or it says,
no, we need to generate other values because those, for any reason, are not something we
can run the assertion on. This way, we narrow down the domain, in this case, the domain
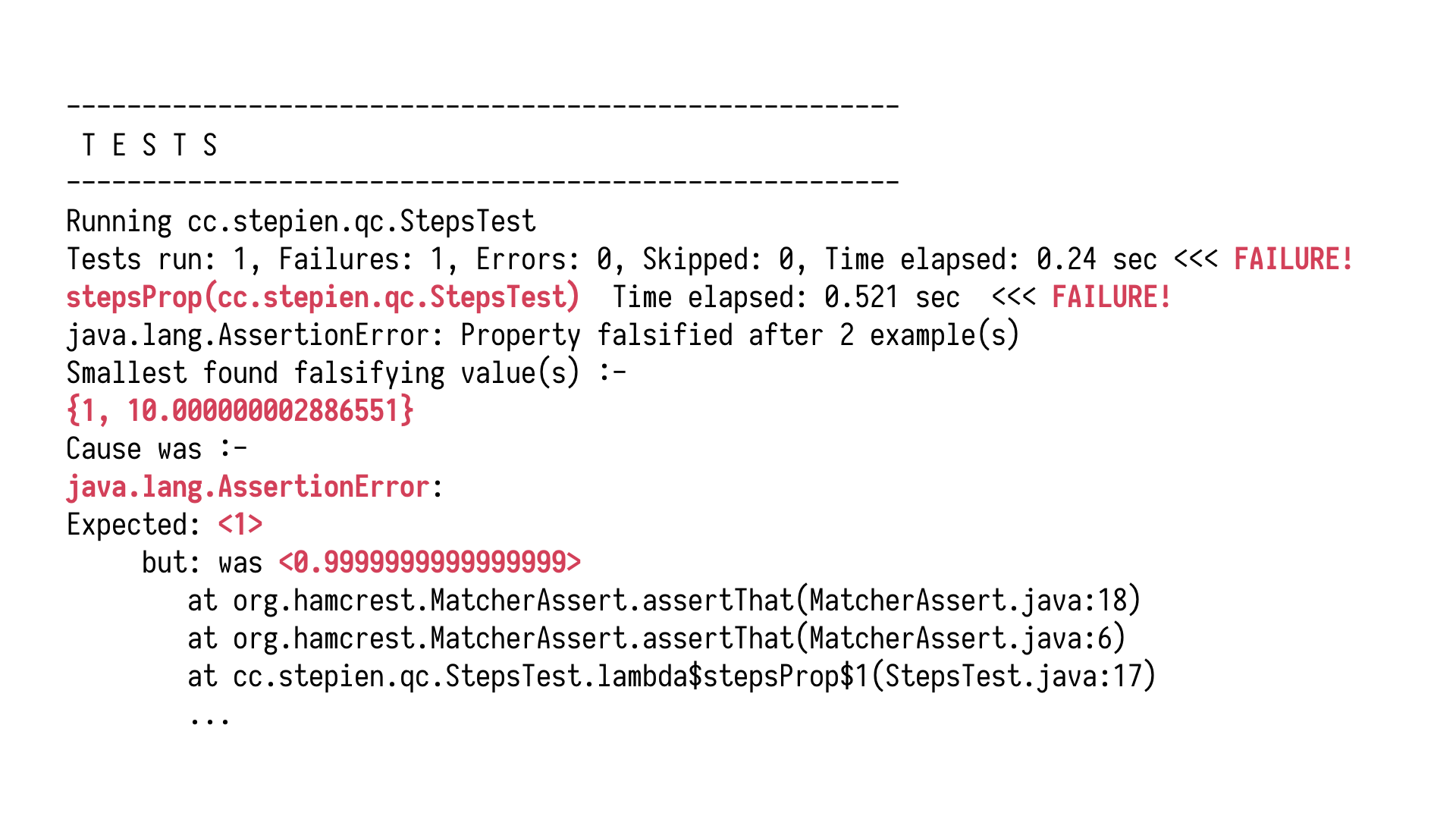
of doubles to what we need. Now, we run this again, quite certain that this time the assertion
holds because why wouldn't it? It doesn't. Our testing library very quickly found some
very exciting values, ten and a tiny bit for which the equality doesn't hold because one is not
nearly one.
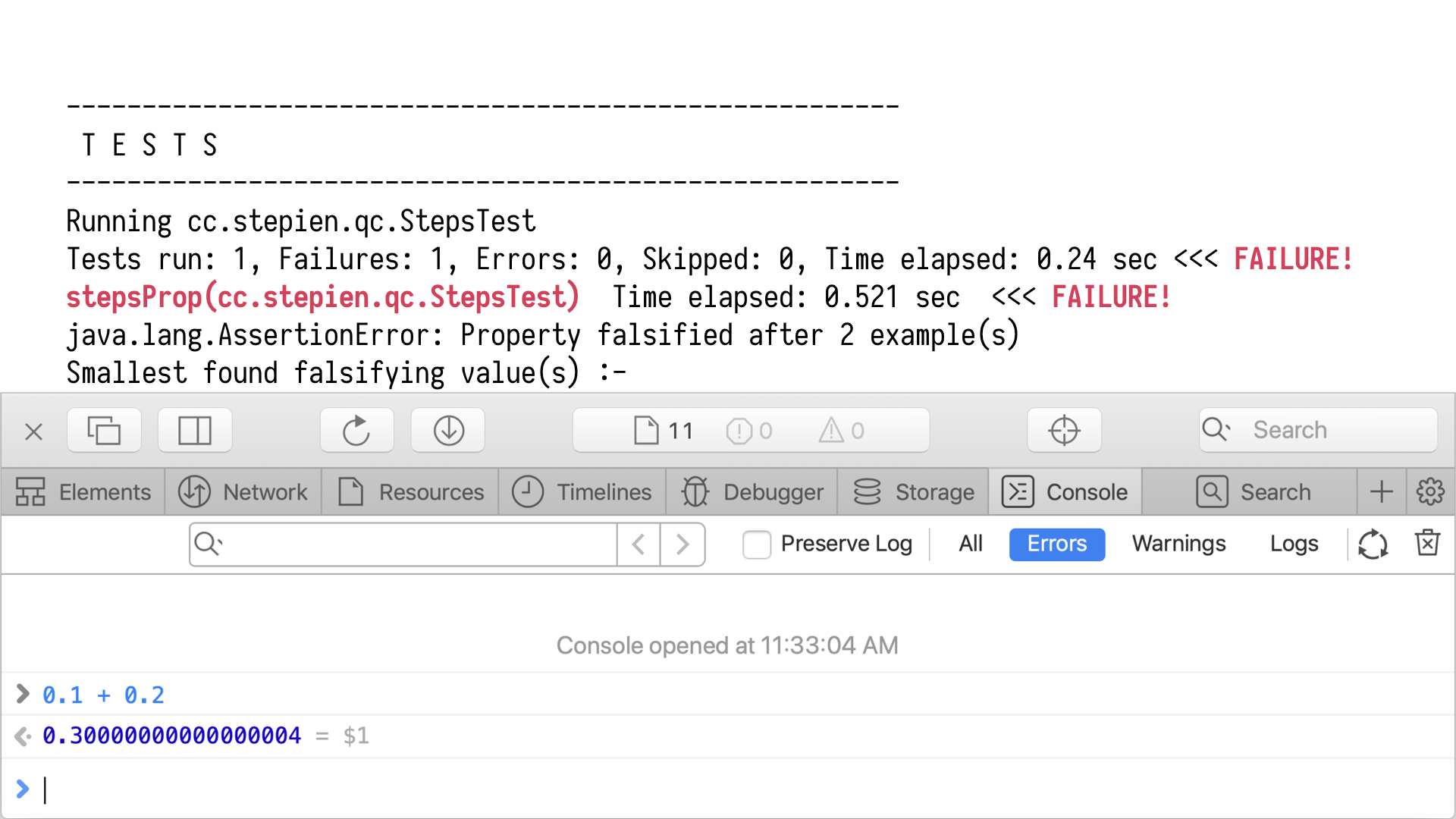
At this point, there's not much we can do, right? We hit something as fundamental
as before. If we fire up our browser console and add two numbers, we realise that computers
and mathematics have very different understanding of addition. There's nothing we can do. We
just have to, again, work with our property and say, well, maybe a better check would
be, say, falls within certain margin of error.
This way, we keep working with our properties,
making them actually describe as accurately as possible the domain that we're testing.
We already see several new degrees of automation. We don't have just automatic execution of
tests. We have automatic generation of values which our properties will be subjected to,
and also automatic generation of edge cases, because we as humans, as developers, are really
bad at testing our own code. We are too optimistic. We need somebody to tell us there is something
in between you haven't thought of, and this tool excels at it, automatically finding mean
combinations of inputs which might result to falsifying our assumptions.
But testing is
not only about automation, right? Those of us who do test-driven development know that
testing is also about design. Having our tests drive us towards an elegant design of the
software. And property-based testing can be also very efficiently, very effectively used
for test-driven development. Let's consider a different example, also a very simple one.
Reversing lists, and by lists, I mean immutable lists—my regards to Grzegorz Piwowarek.
If we want to test drive an implementation of such a simple function, we would also start
with a property. Let's start with lists of longs. And think about the property which
will hold for all the lists of longs which are between zero and ten elements.
What would
we check for? What kind of property holds for reverse? There is no single right answer.
There are several good ideas. What I like to begin with is the fact that if we reverse
twice, we get the same thing back. That's a very nice cycle. It looks silly, but it's
quite valuable because it already conveys the fact that reverse must preserve all the
elements of the list in between calls. All right? Just two calls, just one assertion,
but already quite meaningful property. Let's implement it. Our test is completely red because
there is no code, but let's make this test green by implementing a valid version of reverse.
So we have an entirely wrong function which fully satisfies our properties. So we need
to continue narrowing it down. Think about another property which would make sure that
this is not legal.
Another thing which I thought of is the fact that if you reverse a list
which is not empty, the first thing becomes the last thing. So we can express it like
this. If we have lists of size between 1 and 100, after reversing, the last thing is equal
to the first thing. It turns out that if you run - if you add this property and run
the code, it's surprisingly difficult to write such a reverse function which is invalid.
But let's run it first. We see that our testing library has found a falsifying case, and
look how simple it is. It's just one, zero. It's an example of a value and input list which
falsifies our assumption. But it's not the only example value which our test framework
has considered.
If we scroll down, we will see that a whole lot of other values were
considered. The one at the bottom is the one which the test library stumbled upon and said
this is the first thing which doesn't satisfy the property, or in fact, all the properties
we have here. It said, well, I can give you just that, but instead of giving you something
which might be large and difficult to interpret, it begins to reverse the operation of generators
and begins so-called shrinking. It reduces the magnitude of all the inputs, so, like,
making lists shorter, making numbers smaller, making strings simpler, and tries to generate
a minimal example which still breaks your assumption, which breaks your property. Which
is, again, automation is exactly what we would do.
When we stumble upon a problem, we try
to think, okay, so what actually in this piece of data and the state of the system has led
to the problem? This will automate this process, trying to find it for us, and then it gives
us 1, 0 as a result. This is a minimal thing which breaks your assumptions, and that's
something we can work with.
It's not as impressive when we're working with lists of ints and
strings, but consider the fact that given simple generators of numbers and simple generators
of strings, we can combine those and generate arbitrarily complex data from our domain,
like, say, a customer which is making an order in our shop. When you look at it, and
after you serialise it as JSON, it's just strings and numbers. Some strings looking
like dates. In the end, it's all plain data.
By combining generators, you can generate
arbitrarily complex instances of objects from your domain, and then subject them to
various properties, discovered together with your domain experts. I think since we've already
stumbled into the world of e-commerce, allow me to bring an example.
A while ago, I worked
with a German e-commerce website, and, as customers browsed the catalogue, they ended
up on those pages with those complex addresses representing all the potential filters you
can apply to the databases. Those URLs were parsed into objects representing queries
which would be then sent to, say, Elasticsearch. The logic for, firstly, parsing those URLs
into filters to apply to the database, but even more so for generating valid URLs, this
was a source of regressions, endless complexity, and problems.
There was a lot of stuff going
on there, because we had both like your standard complexity of mapping one structure to a string
representation. We had all the constraints and requirements from SEO department which
had a very clear vision how those URLs should look like, which ones are legal, which ones
are not. Finally, this website was running in a couple of countries, so we had it all
internationalised per country.
We knew we needed to rewrite this module. It wasn't
clear how and what to begin with because there was no reasonable test coverage. We decided
before we start the refactoring, we have very solid coverage of this system. This is when
we reached for property-based testing. So we looked at a problem and said what kind
of property can we discover, can we express using our property-based testing libraries?
And the property is here on the screen. You've seen it before. It has something to do with
the reverse function. If you generate an arbitrary valid descriptor, the object on the bottom
of the slide, you generate a string out of it and you parse the string again, you have
exactly the same object.
So we have this cycle again. And what we did, we expressed exactly
this property that, for all arbitrary search filters descriptors, if you generate a URL
and parse it, we have a quality check. This single property has been an endless source
of caught regressions, fixed bugs. It helped us immensely during the refactoring. We even
were able to come to our colleagues from the SEO department and say, "We can't implement
it. We're sorry." Given this requirement and this requirement, we have this specific
data structure, this specific search, and we see a conflict that those two are mutually
incompatible. This was just fantastic.
Also, the understanding of rules, our colleagues
who work with the domain defined, and the test framework which assisted us in encoding
those rules, and also how it drove our implementation. We started with a minimal generator which
generated just simplest possible search terms, search data structures, and, as we got this
thing right, we kept adding more and more complex generators leading to discovering
various interactions between parts of this logic.
It was just an excellent experience.
This leads me to calling this property-based testing an excellent, maybe not replacement,
but something which accompanies test-driven development very well, where you drive your
tests, where you drive your implementation using properties. This leads not only to better
design, but also to a better understanding of your domain, because, to come up with a
couple of examples, and encode them as a single example-based test, it is relatively easy
compared to how much you have to invest in terms of time and understanding to work with
your colleagues and find general properties spanning the entire system. You understand
the domain you work with far better through this process.
Okay, very well. So we've already
seen some basic principles. As we keep Slido in mind, let's notice that, so far, we were
only looking at systems which were far remvoed from, so to speak, real life. There was nothing
moving inside. There was no change happening. There was no time affecting the system, no
mutable state. There was no real change of the state happening. Can property-based testing
assist us in testing stateful systems which change as time passes? It turns out, the approach,
the property-based approach is surprisingly effective at testing such complex systems.
As we discussed, we can generate arbitrary instances of our business entities of our
domain objects. And if we can generate those instances, we can also generate events describing
change to those instances. Think of all the event-driven architecture talks and keynotes
we've had so far. We can generate an event which describes something that has changed
your system, and if we can generate a single event, we can generate a sequence of them,
apply them to the system, and see whether the system satisfies our properties, satisfies
certain criteria, depending, for example, on the ordering of events, or the fact that
when one event got executed, another one suddenly cannot be reliably executed in the same way
had that previous one not been there.
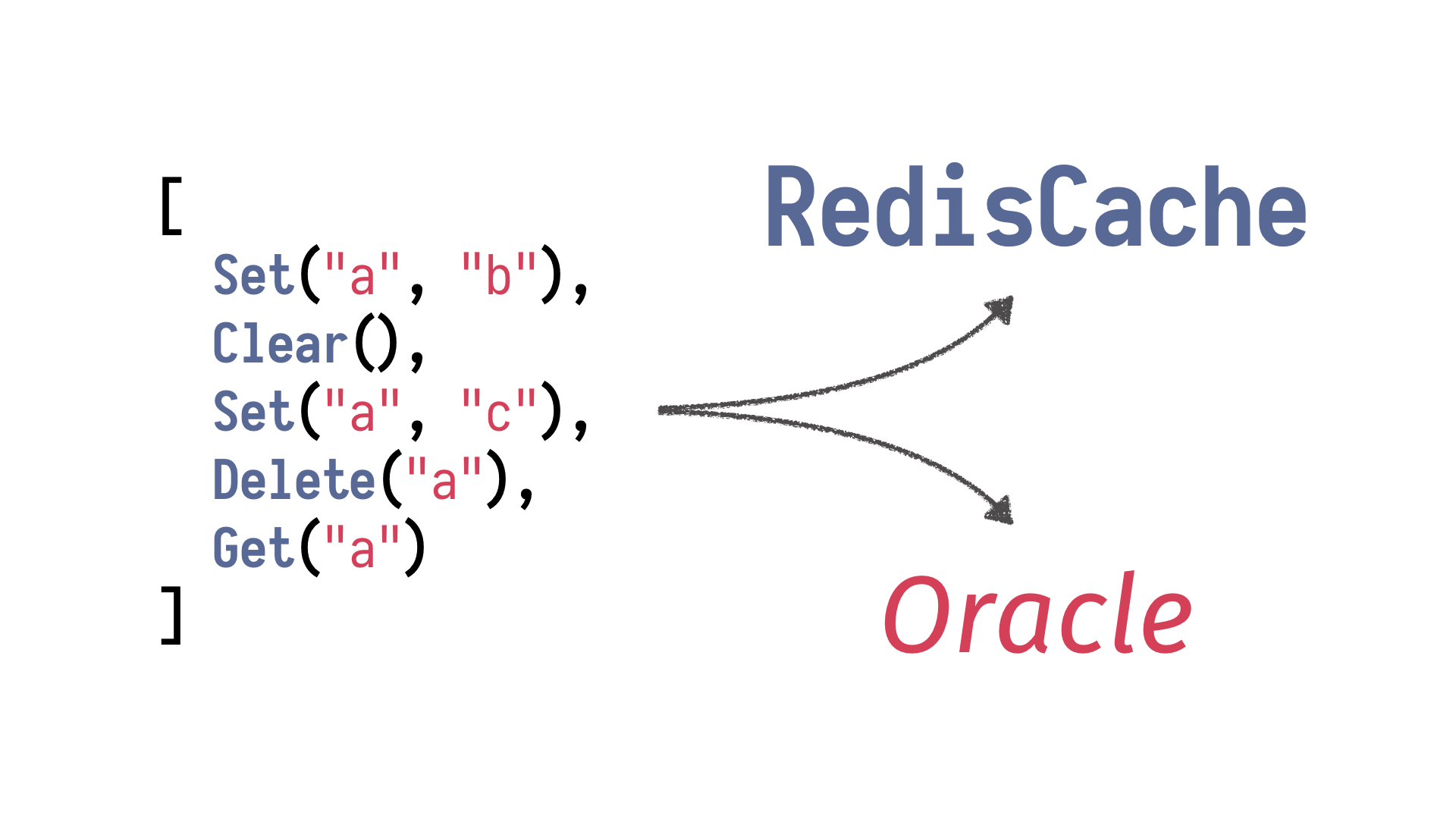
Let's illustrate this approach with a simple example.
Let's implement a facade for Redis. A simple cache where we can save some data and get
some data with a handful of operations, setting a key, getting a value under that key, deleting
a key, and clearing the entire cache. In order to encode those operations as data, we need
to somehow encode the idea of an operation and then simple classes, simple plain old
objects describing those changes.
We have an operation, and then a set class which sets
a given value at a key, get, allowing us to obtain it, deleting a key, and clearing the
entire database. And using generators of sequences, generators of strings, we can generate arbitrary
instances of those operations as well as entire sequences of operations which will
be executed. And then we need some sort of interpretation mechanism which will take those
sequences and interpret them, run them against our system under test, against our class with
a Redis backing it somewhere on the network. And now, the Redis is in some state
after this run, and those operations brought some results, returned some values.
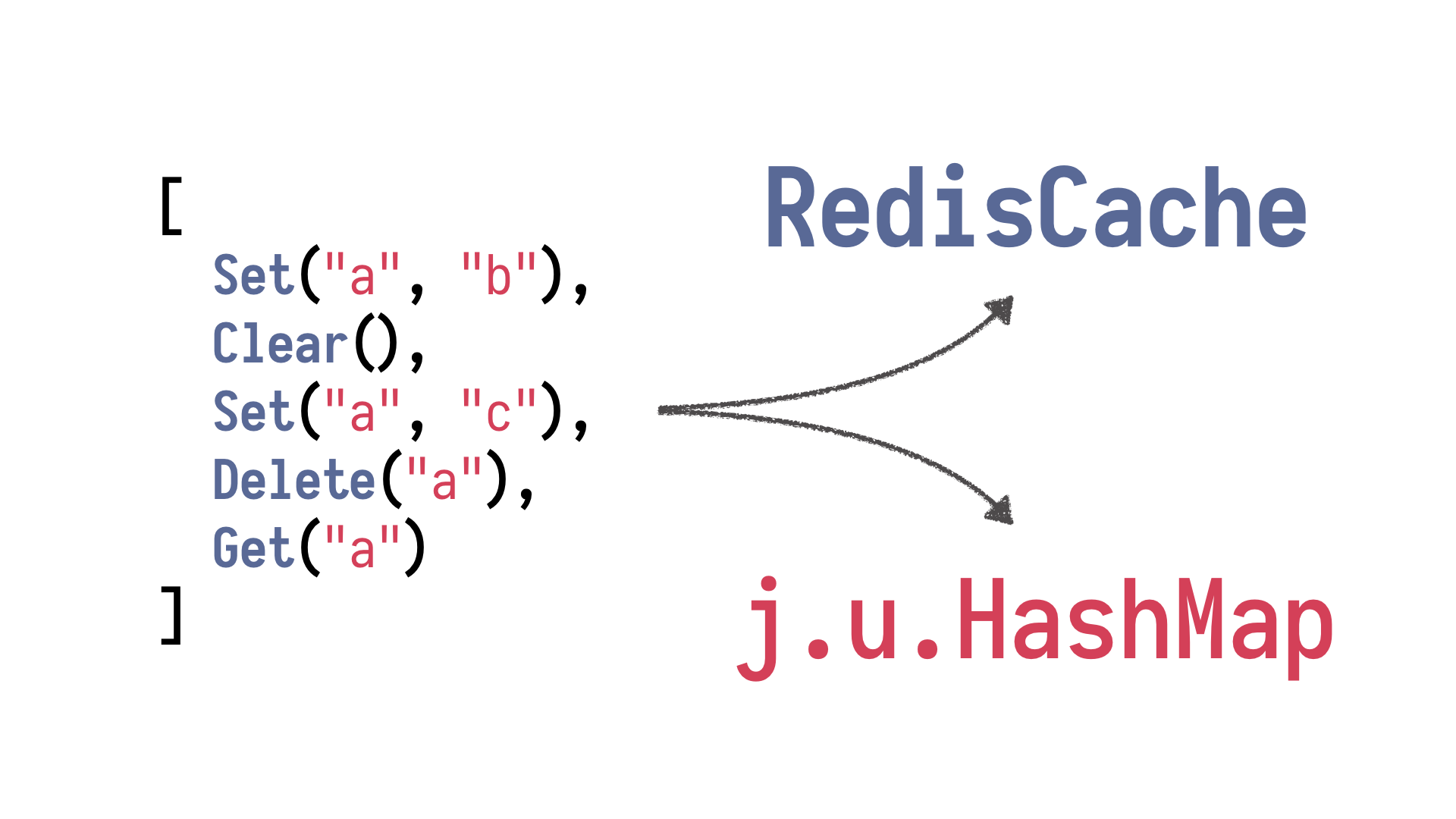
What we
need now is an oracle, and by oracle, I mean this medium, this person who stands between
us and divine entities whom we can ask is our implementation rubbish? And we run our
tests, we run our sequence of operations against Redis cache and our oracle being java.util.HashMap.
And HashMap is a simplified but fairly correct model of the system under test. It models
it without all the complexity, and we can trust it to be correct. Right? We run both
versions, and if - and we define certain post conditions.
For example, every single operation
has to return the same result as it does against HashMap. And if it doesn't, then the test
fails and shrinking begins, and the test framework begins to shrink and simplify our sequence
of operations, resulting, yielding the smallest possible sequence leading to a problem. Right?
Simplification of multi-step debugging of a complex system.
If
you want to learn more about this approach, I heartily recommend this presentation, testing
the hard stuff and staying sane. John Hughes is one of the authors of property-based testing
and works a lot with this method. He's founded a company which is providing services around
property-based testing and speaks a lot at conferences.
He's a brilliant guy. His talks
are entertaining because he takes examples from the industry, and they're frightening
sometimes. He's contracted, say, in this talk, I don't want to spoil too much because it's
a good talk, but he's describing a contract where they were testing internal communication
bus in cars and automotive industry, and they discovered that the protocol connecting various
subsystems of a car, and there is a lot of them these days, have problems of prioritising
messages, so you really, really shouldn't fiddle with your volume as you're breaking.
It's just beautiful.
And it's all thanks to, you know, tools where various sequences of
complex operations are ran against such a massive system, and then minimised into very
real problems. Yes, so watch this stuff and watch other things which John Hughes has to
offer. In the meantime, we talked about state, right? State is exciting on its own.
Things
are changing. The system is evolving. But state becomes really, really interesting when
it's concurrent and multi-threaded. And this is when things get really complex because
we have absolutely no idea what is going on. And this might lead to deadlocks. This might
lead to unexpected values. This might lead to race conditions, problems which occur when
actions executed concurrently aren't isolated from one another and affect one another, where
a sequential execution of actions wouldn't lead to a result which we have observed in
a concurrent environment.
And, again, a question, can property-based testing help us testing
concurrent stateful systems? Let's think at what does it mean to have a concurrent stateful
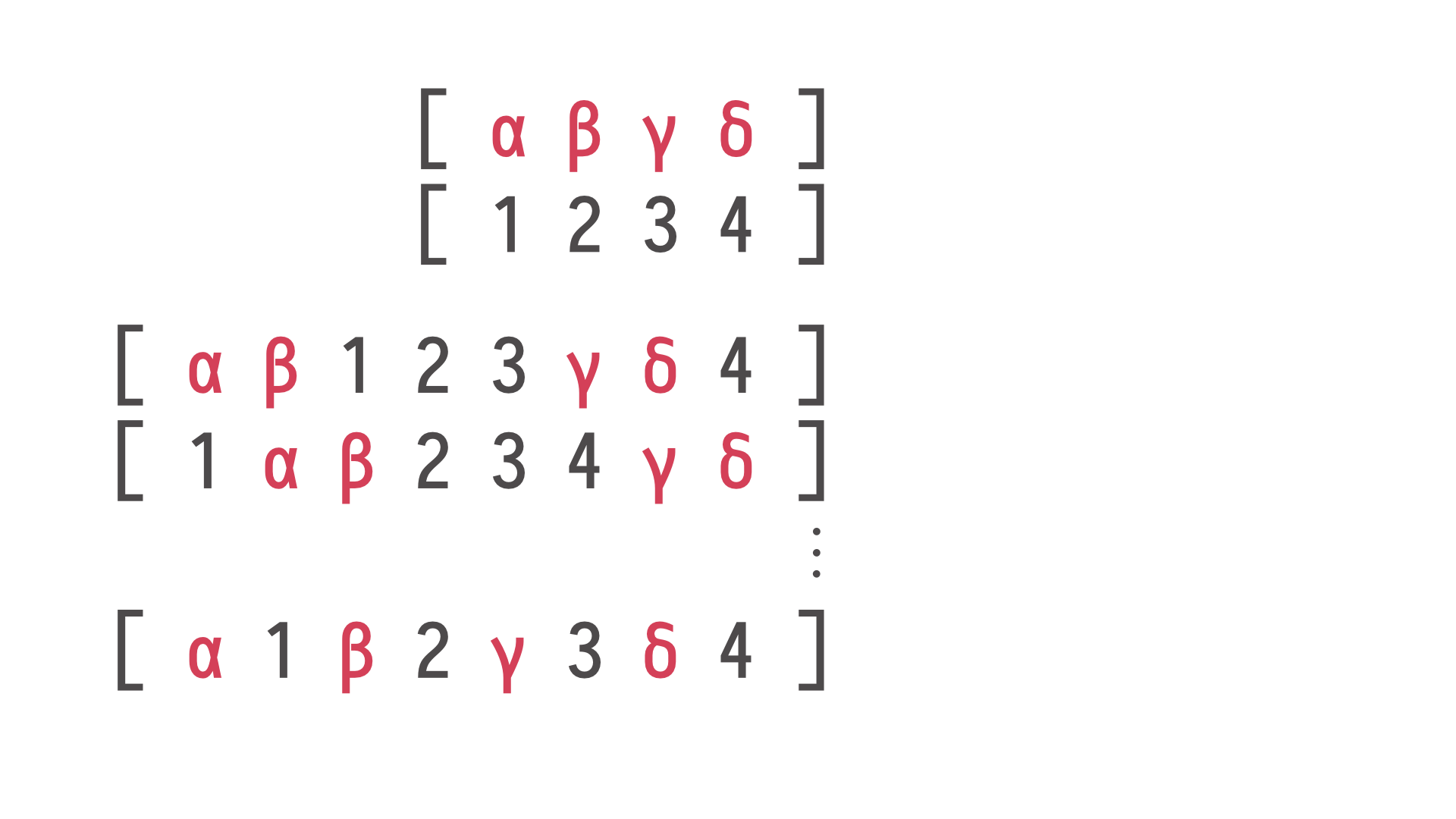
system? It means that we have, for example, two threads, the Greek thread and the Arabic
thread, and they execute four operations each at the same time concurrently. We have no
idea what the order will be. We have a single system, for example, Redis cache, and we
execute all those operations from two threads.
The system ended up in some state. But we
know that if those operations, if those two threads have no - don't have any impact on
each other, don't affect each other's execution, the resulting state should be the same as
if those operations were executed in some interleaving. This individual subsequences
are preserved, the order is preserved, but we don't know how individual threads interleaved
their execution.
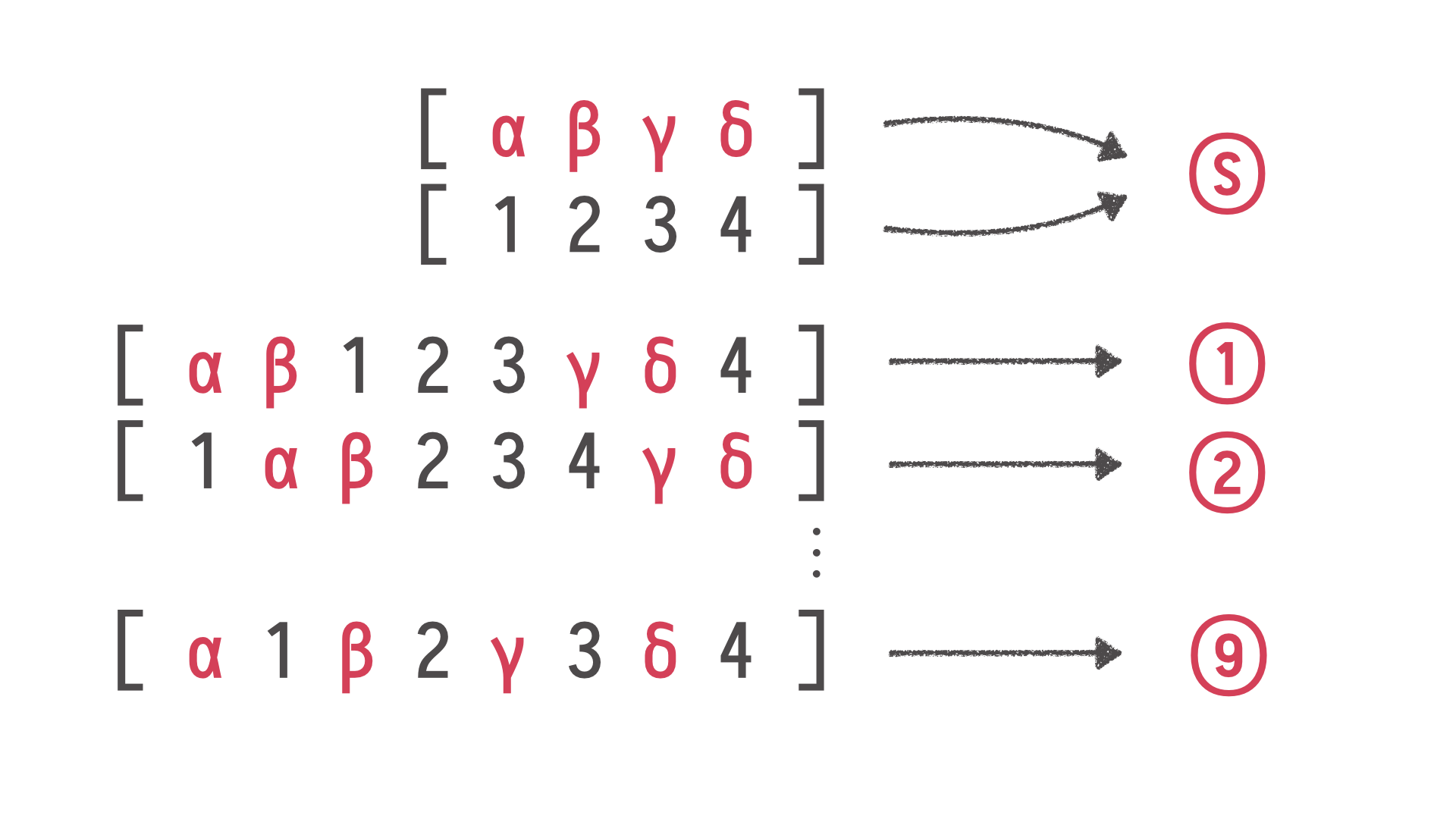
I hope everybody is following me so far because it is getting more exciting.
We have our case with two threads, and we put those two sequences of operations we generated
of our framework, put them into two threads which are waiting behind some kind of lock,
and then we say go. Those two threads execute those operations, and something happened,
and we ended up in a state S. Our Redis cache is in a state S. Those two threads yielded
values; we can call them S.
Now, we know that if there were no interactions between those
two threads, then those operations were interleaved somehow. So S must be either the result of
execution in this order, or the result of execution in that order, or many other possible
orders.
The number very quickly gets big. So we know that sequential
executions have brought us to those, in this case, nine states. In practice, many, many
more. If S is not a member of this state, of this set, if we can't find S among sequential
executions, we know that the result of the concurrent execution has been affected by
the concurrent environment. There was some kind of race condition, some kind of interaction
between those threads which led to an unexpected result.
This is again something which John
Hughes talks about, testing next-step concurrent stateful systems. It's fascinating because
he shows in another talk of his fascinating examples of complex systems such as thread
pools and distributed databases which, depending on certain interleaving of operations, yields
inexplicable results.
With tools such as these, you can find those cases. Of course,
one important thing is we have to remember that we are dealing with non-determinism.
We have no idea whether we will see that S ever again because there is a chance that
such an interleaving of threads, such decisions of our CPU scheduler will never happen again.
So, when we begin to shrink those sequences of operations, what happens if, for example,
in the next step of shrinking, we will never see the same sequence again, we will just
never see the same problem again? Again, what John Hughes advises here is simply just run
the test ten times. It's more than likely that one of those executions will manifest
the same problem.
On JVM, we have - JVM is a wonderful beast but it has certain limitations.
For example, we don't really have such a fine-grained control over threads and their execution as
on other platforms. For example, if you work on top of the Erlang virtual machine, you
can control threads at a far finer level and actually force the virtual machine to
perform certain interleavings of those threads which makes this process far faster than running
it ten times and hoping that it will work. But still, in any case, we're standing on
the shoulders of giants.
I would like to illustrate this approach with another example. Who here
knows Jepsen and Kyle Kingsbury's work? I see some hands. This is just brilliant. Kyle
Kingsbury is a man who is grilling databases.
What he does is he takes some kind of distributed
database we all here know and trust, and he reads carefully the documentation of the database.
What happens if problems occur, if networking problems occur, if there are glitches, if
suddenly half of your cluster is disconnected from the rest? Then he reads the guarantees
which authors of the database offer in such conditions. Then he replicates exactly those
conditions in his test cluster which he has full control of because it's a bunch of virtual
machines.
He injects glitches into the network connecting database nodes. He's injecting
delays, other problems, half of the cluster is invisible, and so on. Then just generates
sequences of simple operations. It looks whether the result after the partitions are healed
after the database is back in a stable state, whether the contents of the database can be
explained by what's there in the documentation.
Kyle has given a number of talks and wrote
some excellent very deep technical articles about various databases. I don't want to name
but you know them and you use them. I can only recommend reading those and realising
that sometimes we have to trust, but sometimes we should also verify. It's really fantastic
what is happening. Such, in principle, simple methods, how far they can bring. This is nowhere
as powerful as a formal proof that something is correct or not. It's just firing random
tests and more often than not, you find problems which occur in such settings.
My friend, I
want you to be better at testing. Your tests as they are, they totally work. But keep in
mind that if you run into some really complex problems, really demanding, challenging systems
under test, there are tools for that. There are tools which allow you to automate not
only testing itself but also generation of various mean inputs to your logic. But also
automate the process of reducing those failing cases to a minimal thing you can work with,
you can debug. It's not five kilobytes of JSON. Good luck, debug this. No, you have
a minimal thing and you know that everything in this thing had somehow impact on the invalid
state of the system.
And as Daniel told us in his talk just yesterday, automate all the
things which computers can do for us. This is such an excellent example of things which
computers can do for us with advanced enough tooling. And also, keep the design in mind.
The fact that simple properties, few properties can already narrow down our design and help
us implement elegant systems just like we would do using test-driven development.
But
in this test-driven cycle, as we write a property and a simple generator just covering a small
chunk of a domain, we hope we got our implementation right and the property says no, no, no, here's
another example, now fix this, now fix that. We have more and more things to work with.
Once the test is actually green, we can switch to a different property or expand the scope
of our generator covering the larger chunk of our domain.
And all those things in the
end taken together finally lead us to quality. But quality is not a direct result of testing.
It's a consequence of a number of choices around automation, around design, around choice
of tooling which for a given case can allow us to really speed up the testing and verification
process.
Okay, my friends, if you have any questions, I have an email address, I'm on
Twitter and if you need any other links, they're all at my website. So, if you haven't written
any questions on Slido, just shoot them over there. I'll be more than happy to get back
to you later, and with this being said, this is all I've got. You've been a wonderful audience.
Thank you all so much.