Machine transcript
My name is Jan. I'm based in Berlin and I'm a consultant at INNOQ. I'm here to talk
about GraalVM, this new exciting piece of technology released just in April, coming
from Oracle. The package itself comes with a whole lot of exciting contents. There is
an entire new JVM with new just-in-time compiler, Node.js implementation, polyglot tooling
and a lot of other things I don't have time to talk about. If you're interested in those,
let's talk in the hallway track.
Now I'm going to focus just on the most exciting bit
from my point of view, which is the native image generation, translation of JVM bytecode
into native images, which brings us directly to native Clojure. If we get the package
off GitHub, we will download this 200 megabytes worth of a binary blob with virtual machines
implementations of a whole lot of various programming languages, including C and C++
through LLVM support.
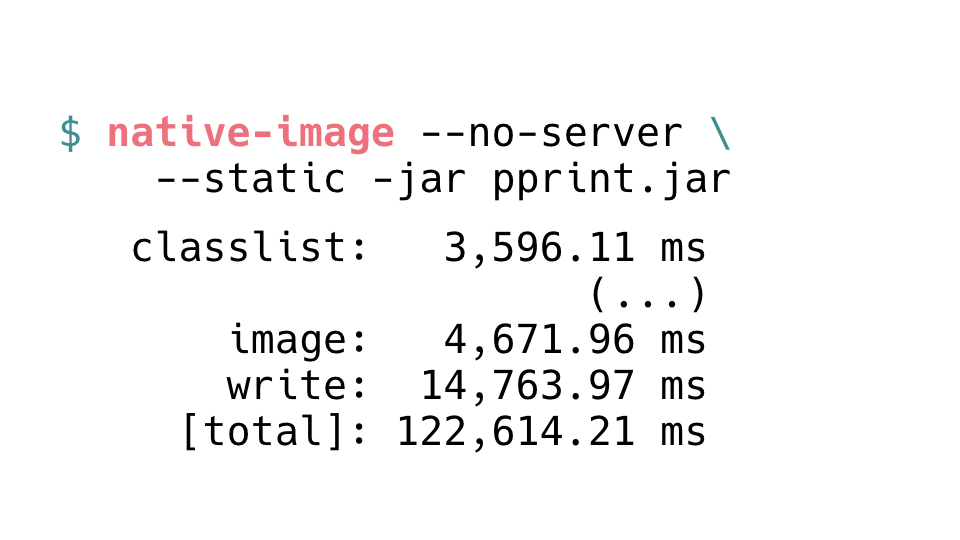
Using this package, we can try to compile a simple command line
utility, a wrapper around something like jq, but for EDN data structures. The path comes
as the command line argument. The data structure comes from the standard input. We print the
result on the standard output. We can compile this piece of Clojure and translate to Java
class files, build an uberjar, and we execute it on JVM.
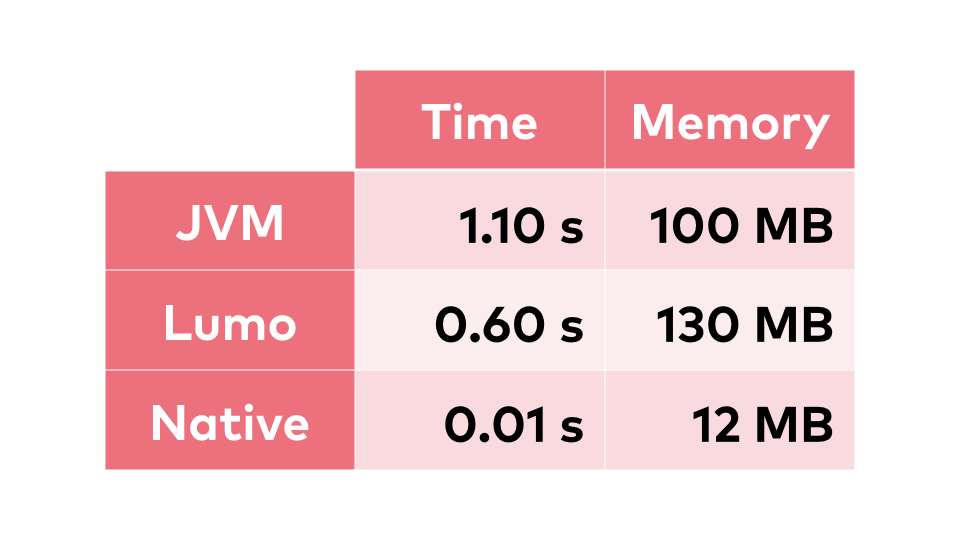
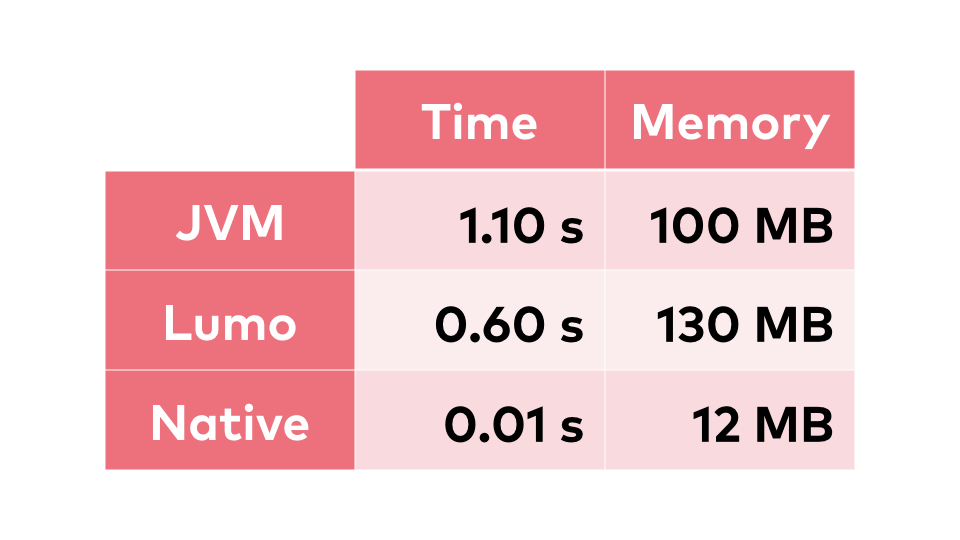
We're around one and a half second
by default. If we add some extra parameters, JVM is a very flexible machine, we can get
it down to one second. This is our baseline state of the art as of today. We can invest
a bit more time, rewrite the thing in ClojureScript and use Lumo, which is a brilliant
piece of engineering. This halves the time necessary to execute the same
programme.
Now,
let's use native image. It's this binary coming as part of the Graal package, translating
the contents of our uberjar into native binary. And the result completely removes the start-up
time of the application. It brings it to ten milliseconds, not to mention the RAM necessary
to execute the programme. If we compare, we clearly see that this is a massive change,
and as a result, we can see for a whole variety of programmes we will compile and run using
this tool. Before we try to answer how is that even possible, let's focus on potential
use cases and what kind of new avenues this piece of technology
enables.
Let's start
with command line utilities. I'm a fan of UNIX pipelines and passing text between various
processes, doing one thing, doing it well. And this tool, Graal, enables us to introduce
the same approach to implement Clojure-specific tooling. For example, a sample programme
translating JSON to EDN, right? We keep reading JSON objects from standard input until we
hit end of file. Potentially, the stream is endless, it doesn't matter, and we keep lazily
printing all the results on the standard output.
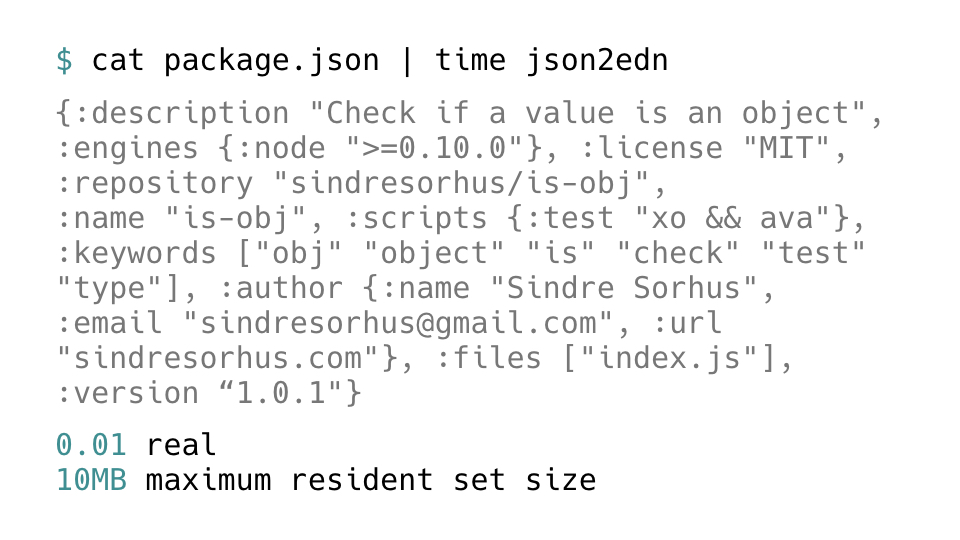
We can pre-compile the thing into an uberjar
and then generate a native binary for this programme, and if we take some random
package.json we found on my disk, we end up with similar numbers, and a corresponding
EDN representation of the JSON data structure.
Let's extend this UNIX pipeline. We can add
spec provider which is this fascinating library I stumbled upon not long ago. What Status
did here is got inspired by F# and its providers. Let me borrow an example from his readme file.
You take a couple of data structures, a sequence, and ask the library to
infer a clojure.spec
schema specification covering all those samples, and then you can print it, and you see that
your small map is something with keys a, b, c, a being an integer, b being a string,
and c being a keyword or a string which corresponds exactly to what we see
above.
Let's wrap
it in a small command line utility. A very similar story, right? I am reading input from
the standard input, deserialising EDN data structures, then passing the entire sequence
which in this case cannot be infinite, passing it to infer the specs, and printing all the specs
on the standard output.
Before we run it and see it in action, let's add one more tool,
a pretty-printer allowing us to nicely format the resulting code. It can be
cljfmt,
but it can be zprint which Martin mentioned in an earlier presentation. In this case,
I don't need to do anything because zprint comes out of the box with precompiled native
image binaries, so I just have to download the native image for my target platform and
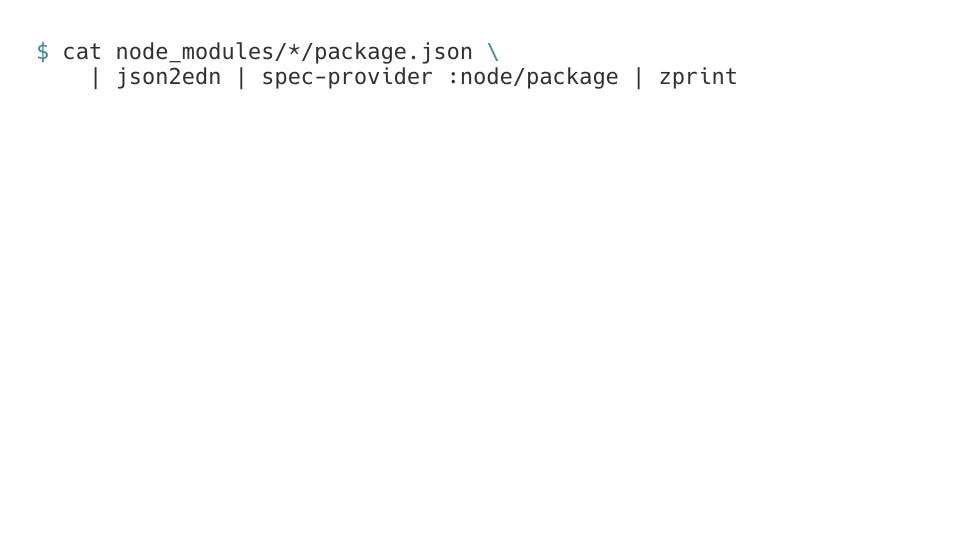
I can just plug it into my pipeline, which in the end will look like this. I will get
a handful of package.json files, translate all of them to EDN, run spec provider to
infer a spec of a handful of package.json files, and finally pretty-print the result, obtaining
more or less something like this within half a second. Instead of running three separate
JVMs, the job is done in half a second and using relatively little RAM in the end. And
the resulting code can be directly copy pasted into our source files.
So that's one exciting
use case, right? We can build Clojure-specific EDN specific tooling without sacrificing
this short feedback loop of having native binaries for a target platform, being able
to run them very quickly and not waiting for the start-up time. Ideas that come to
mind are tools like REPL clients like Unravel which connects to a TCP nREPL within fractions
of a second. It can be a tool for project management, processing your project.clj or
deps.edn file to check for updated dependencies, for instance. But let's take a look at a different
use case and different part of the ecosystem, specifically about web application with focus
on their deployment aspect.
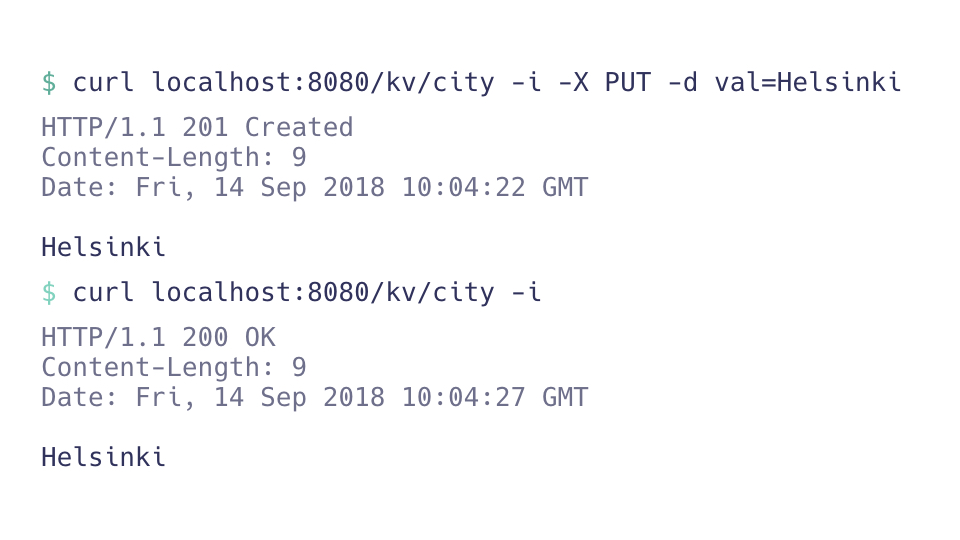
Let's write a simple web application which can support the
following API. I don't need much. I just want a key value database. I can store a value, and
I can read a value, and that's it, right? It would be lovely if the thing could persist
the data and the temp directory between restarts of the server. To implement this, I don't
need a lot of code. I don't expect you to read it. It's way too small. All I want to
show here is that I need maybe 50 lines of code to combine bidi, http-kit, and some ring middlewares
to implement this whole use case I showed a slide before in the previous slide
and precompile it to, first of all, a proper Clojure, and then finally to a native image
which ends up being 7 megabytes in size, a 7-megabyte library, a native
binary.
And
now, instead of trying to run it and looking at runtime characteristics, let's try to package
it. Let's say to wrap it with - wrap it in a Docker container. We will start with Ubuntu
as our base image. We will install all necessary dependencies which we need for precompiling
Clojure projects using Leiningen and then necessary tooling around GraalVM. Once that
thing is in place, we can add all project-specific files and build our uberjar. Finally, in
the last step, we are building our native image, this big binary blob, adding all the
parameters just like you saw in the previous invocations. We end up with this statically
compiled file. But we're not done yet. Here we are doing the twist and starting from scratch
again, which means we are starting all over again from a completely empty base Docker
image with not a single file on it, and using the copy instruction, we are copying web
key value main from the previous image into the new one. And we end up with a Docker image
which consists just of a single file, our static, self-contained binary without any
dependencies on it.
The resulting file, the resulting Docker file is 13 megabytes in size.
Just to offer a comparison, the smallest JVM I was able to find on Docker Hub was around
70 megabytes. And in those 13 megabytes, we have all we need and nothing else. We don't
have the entire operating system. We don't have all the things which could potentially
cause problems or security concerns in production environments are gone. It's just our static
native binary inside.
So, this naturally leads to the question,
how is any of it even remotely possible, right? There must be some magic or at least three
small pieces of magic involved. Let's look at numbers again. We can kind of understand
the memory difference here. We have to keep in mind that this native image doesn't have
a virtual machine any more, right? All of our JVM bytecode gets translated as partially
optimised and translated ahead of time into native code.
So, all the machinery necessary
to compile code just in time, an entire just-in-time compiler, tooling for loading classes, for
running all this dynamic code is not necessary any more. All we need in the end is a garbage
collector because resulting binaries have a garbage collector just like you have in
a normal JVM environment.
So, this makes sense, right? The first row, we need the entire JVM.
Second row, we need the entire V8 with all the machinery for just-in-time compilation.
But this is something far trickier to explain. And to dig deeper into the reason behind this
massive gain, which is especially pronounced in the case of Clojure, we have to go through
some blog archives.
The year was 2014, and Nicolas wrote this very interesting series
of blog posts about how Clojure starts up, how it initialises its classes, and how - where
is the actual cost of start-up Clojure applications? And, in particular, in this piece, we can
read about the representation of JVM classes which come as a result of
Clojure compilation.
It turns out that most of the cost is happening in those static class initialisers. Those
pieces of code which are executed when the class loader is loading our class to memory.
What's happening in those static class initialisers, the Java construct, is recreation of all of
our namespaces. Creation of the namespace itself. Definition of all the vars we have.
Attachment of values to vars. Attachment of metadata to vars. All of those things happen
in those - here you see decompiled output.
In those static class initialisers. The way
GraalVM can optimise the start-up time so well is by running all of those static initialisers,
all the static code ahead of time. Not at the time of run time like on a normal JVM,
like on a normal Java environment. Instead, all of this initialisation is happening at
compile time. It aggressively tries to find, starting from your main function, main namespace,
tries to find all the bits and pieces of your own application, of your own code, of all
the dependencies you're using, and of the JVM itself, of the JDK itself, all the parts
of the Java standard library, trying to find them ahead of time, collecting all those static
initialisers and running them and then compiling into your native binary just those initialised
ready namespaces filled with all your vars and so on.
Suddenly, the entire cost of initialisation
of a Clojure project disappears because it happens at compile time. What is important
is that if at compile time you're opening a connection to a database, using a def instead
of something happening at run time, it will happen at the image creation time, which is
in most cases not what you actually wanted.
If you would like to learn more about the
process itself, check out a recent blog post by one of the authors of Graal where he goes
deep into the process of how those static initialisers are executed, how are they - how
and when are they executed, and how can you control this execution, leaving, for example,
some parts of your code, some bits uninitialised, and having some others initialised as eagerly
as possible, controlling which parts need to be loaded later and which ones can be optimised
up front. It's especially interesting if you compare this blog post to the one written
by Nicholas and compare how those two bits fit together.
Before we get too excited, let's
talk about problems. There are some limitations we have to keep in mind. The GraalVM team
is maintaining this file about Substrate VM limitations. Substrate VM is this very thin
virtual machine embedded into every single binary which is produced by the native image
command. It's essentially a garbage collector and not much more. They list a whole range
of potentially problematic mechanisms which are not fully supported by Substrate VM, but
when you take a close look, you realise that, in our case, in the Clojure case, we're not
that much affected by those problems.
Let's talk about reflection. Clojure is surprisingly
reflection-free, or rather surprisingly easy to analyse statically by tooling such as
native image in comparison to, for example, a modern Java application relying on Spring
where a whole lot of work is happening at run time using annotations and reflection.
In the case of Clojure, we can fairly easily get rid of reflection by using tools such
as *warn-on-reflection*. It doesn't apply that much to our case.
Another thing which is a big
no-no is dynamic class loading. There is no virtual machine any more in those pre-compiled
images, so there is nothing to load your classes, load your code into, so all the things such
as require eval and other functions which allow you to load or execute code have to
happen ahead of time. You can't do them at run time. Which sure is a massive constraint
at development time, but I believe in the strong majority of cases does not happen in
production environment, allowing us to use GraalVM in production without much concern
when it comes to this point.
If you want to give it a try, I encourage you to check out
Taylor Wood's tooling to save you all the invocations of native image itself, you can just download
either a Leiningen plug-in or CLI tools plug-in allowing you to perform all those native compilations
as part of your pipeline straight from your project.clj or deps.edn file. Yes, I encourage
you to experiment. This is a completely new piece of technology which opens a new avenue
for us to try, to experiment, to see how Clojure fits into either our command line tooling,
allowing us to very quickly process stuff at the - immediately in our terminal, or,
in those lightweight web applications, if you have a situation where your memory usage
is constrained, there is one fit. If you have a situation where you need a quick start-up,
or think about an Electron application which, instead of shipping a whole virtual machine
for its back-end part, ships just this - just a handful of platform-specific binaries implementing
all the functionality and starting up way faster.
So, as I said, I encourage you to
experiment, to give it a go. I just touched the tip of the iceberg and gave you a number
of very simple examples. Try it on your code, see it work, see it break, and also try out
other things which are part of the GraalVM. There is much more to discover inside, and
I can only encourage you to experiment. This is all I've got for today. You've been a wonderful
audience. Thank you very much.